
Dataset Dev: Dec 2021 Update

Much of the work in the first year of the project is centered on data set development. This includes identification of data sources, normalization of data for common resolution across the six watersheds and reclassification and attribution to support project modelling. The list of datasets below provides an overview of the type of data being assembled to support the modelling initiative. For simplicity the datasets are grouped according to four main themes: i) groundwater-surface water (GW-SW) model construction, ii) atmospheric (historic), iii) atmospheric (climate projection), and iv) remote sensing. Most of these datasets are in the public domain. In fact, given the geographic extent of the project and funding constraints it is only feasible to work with public domain data. An additional challenge relates to the transboundary extension of the model domain into the USA to represent drainage basin boundaries (and not political boundaries). This complicates the data assembly as numerous datasets are available as national products. Harmonization of similar but slightly different data sets can lead to numerous challenges involving nomenclature, differences in data collection protocols, etc. In forthcoming newsletters we will delve into additional details on each of the data groups and some of the individual datasets.
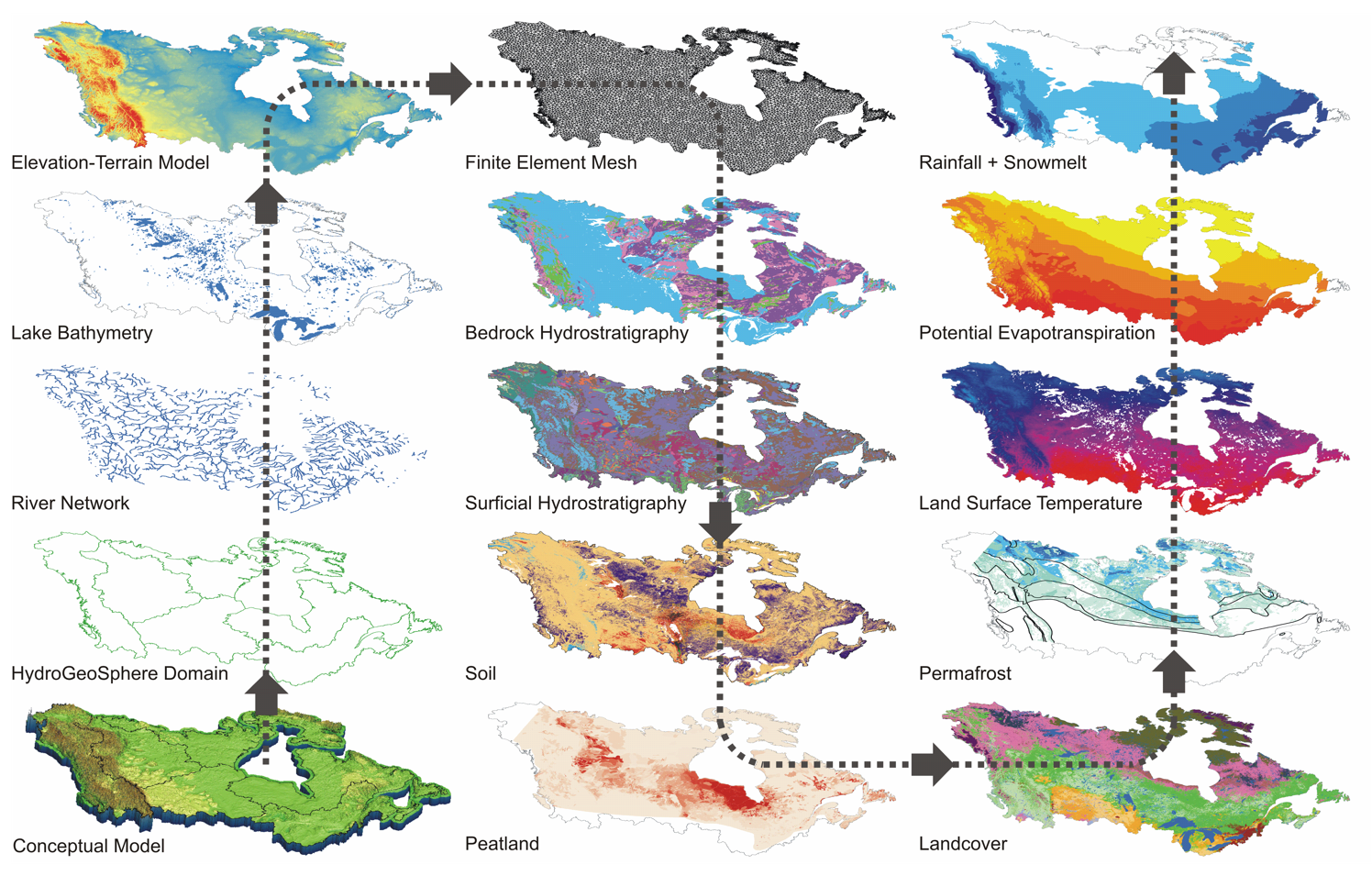
Figure 1: Summary of datasets incorporated into the C1W HydroGeoSphere model assembly process.