
Dataset Dev : Dec 2021 Update

Une grande partie du travail de la première année du projet est centrée sur le développement de l'ensemble des données. Cela comprend l'identification des sources de données, la normalisation des données pour une résolution commune aux six bassins versants, ainsi que la reclassification et l'attribution pour soutenir la modélisation du projet. La liste des ensembles de données ci-dessous donne un aperçu du type de données rassemblées pour soutenir l'initiative de modélisation. Par souci de simplicité, les ensembles de données sont regroupés selon quatre thèmes principaux : i) construction de modèles eaux souterraines-eaux de surface (GW-SW), ii) atmosphérique (historique), iii) atmosphérique (projection climatique), et iv) télédétection. La plupart de ces ensembles de données sont dans le domaine public. En fait, étant donné l'étendue géographique du projet et les contraintes de financement, il n'est possible de travailler qu'avec des données du domaine public. Un défi supplémentaire est lié à l'extension transfrontalière du domaine du modèle aux États-Unis afin de représenter les limites des bassins hydrographiques (et non les frontières politiques). Cela complique l'assemblage des données car de nombreux ensembles de données sont disponibles en tant que produits nationaux. L'harmonisation d'ensembles de données similaires mais légèrement différents peut conduire à de nombreux défis impliquant la nomenclature, les différences dans les protocoles de collecte de données, etc. Dans les prochains bulletins d'information, nous entrerons dans les détails de chacun des groupes de données et de certains des ensembles de données individuels.
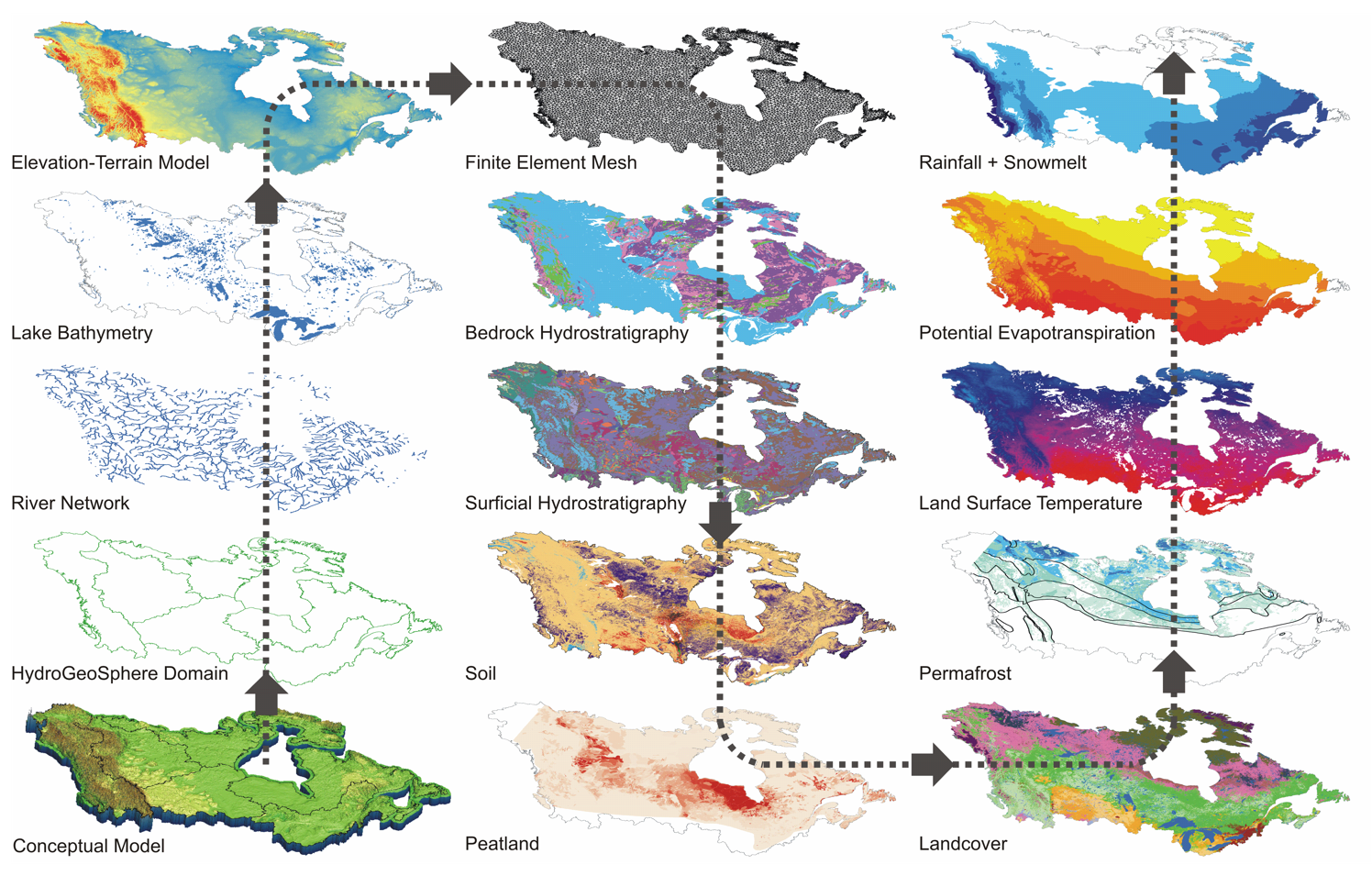
Figure 1 : Résumé des ensembles de données incorporés dans le processus d'assemblage du modèle C1W HydroGeoSphere.